やっとうまく動くようになりました?
パブリッククラウドのOCR機能を使ってみよう第一弾。
なんと、このページからGoogleCloudの Vision APIが実行できます?!!
(このページはVueで書いたのでIEだと動きません。)
?GoogleCloud Vision APIのデモ
毎月、1000回までデモできます。
(1000回に達すると実行されなくなります。無料枠内を超えないように制限してます?♂️)
?解説
いや、まぁ公式サイトでもデモはできるんですけどね。
GoogleCloudではないレンタルサーバーから呼び出しできるようにするのに苦労したので、そのポイントも掻い摘んで解説をしていきますね。
?OCR結果の見方
デモは、「ファイルを選択」で画像を選んだら「VISION API実行」ボタンを押すだけ。
例えば、こんな画像を送ると。。。
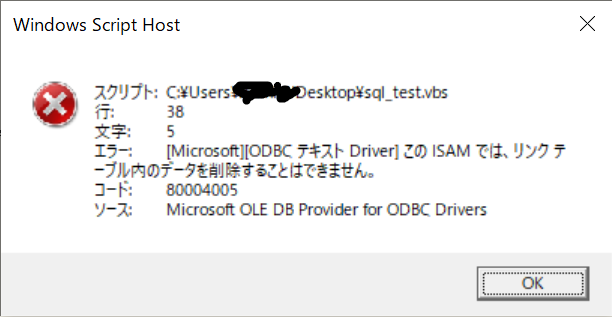
こんなん返ってきて表示されます。
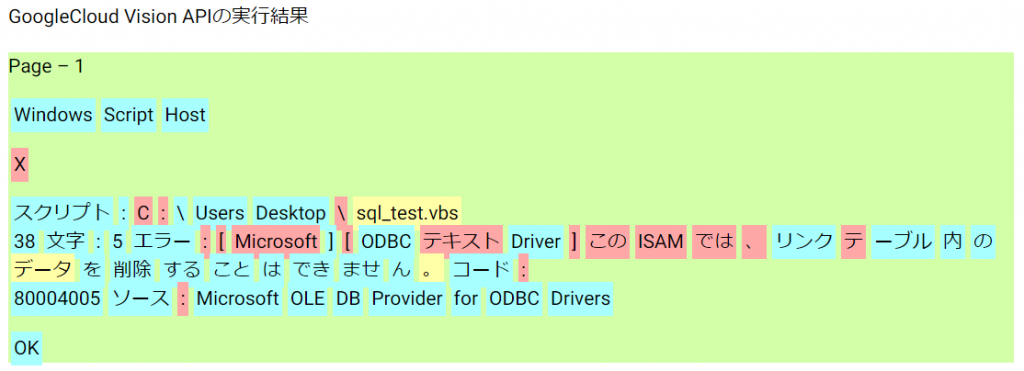
OCRの結果値にはconfidenceという形で、その文字判定の信頼度スコアがセットになって返ってくるので、95%以上は青、90%以上は黄色、90%より下は赤でラベル付けしてみました。
ラベルをオンマウスするとtooltipでスコアが見れるようにしています。
?構成
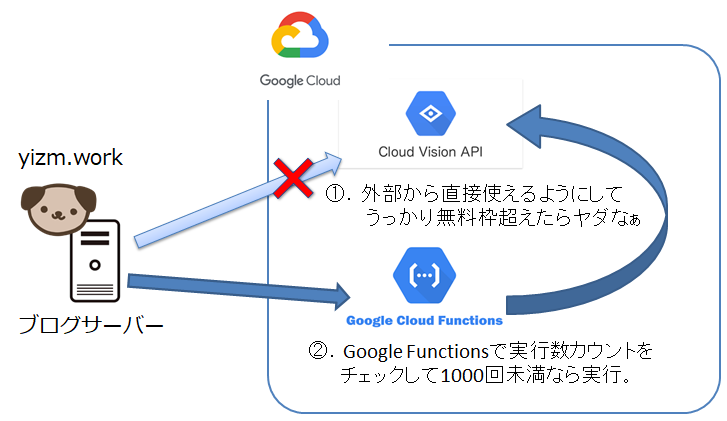
APIを直に公開するとイタズラされてめっちゃ課金来るの怖かったので、Google Cloud Functionsを間に挟んで当月のAPI実行回数をチェックしてから実行する仕組みにしてみました。
最初は、「Google Cloud Vision API と Apps Script を使用して G Suite アプリを構築する」これを見てApps Scriptを使おうと思ったんだけども、Apps Scriptの外部公開っていろいろ制限あって思った感じと違ったんですよねぇ
Googleユーザ同士だとApps Scriptって簡単に活用できるから好きだったんだけども、外部サイトに組み込むとなるとToken取得して、ブラウザのGoogleログイン状況を確認して、っていう2Stepが必ず必要で、誰でもフラッとこのサイト見に来て試してみるっていうのが実装できなかったんです?
Google Cloud Functionsは、毎月200万回実行まで無料枠があるので、Vision API(毎月1000回リクエストまで無料枠)のフィルタになってもらいました?
?Google Cloud Functions側のコード(一部抜粋)
今回は、Pythonで書いてみました。基本は、画像内の手書き入力を検出するを参考にしています。
一応、他の言語の仕様ではbase64エンコードが必要ってなってるんだけどもPythonは明示的にbase64エンコードのコード書かなくてもいけました。
送られてきた画像は、そのままPOSTのfilesからstreamを取り出してread()したものをVision APIのcontentにぶちこんだらうまく動きました。(ここが何気に苦労したよ。。。)
送られてきた画像はストレージ保存せず、そのままVision APIに送って捨ててるので私のストレージ容量も増えなくて助かるし、試しに使ってみる皆さんにも安心の仕様?
import json
import os
from google.cloud import vision
def callVisionGateway(request):
# Set CORS headers for preflight requests
if request.method == 'OPTIONS':
# Allows GET requests from origin https://mydomain.com with
# Authorization header
headers = {
'Access-Control-Allow-Origin': 'https://yizm.work',
'Access-Control-Allow-Methods': 'POST',
'Access-Control-Allow-Headers': 'Content-Type',
'Access-Control-Max-Age': '3600'
}
return ('', 204, headers)
# Set CORS headers for main requests
res_headers = { 'Access-Control-Allow-Origin': 'https://yizm.work' }
rslt = {}
if 'fname' not in request.files:
return ({ "state": "NG", "message": "Try POST Scan Image." }, 200, res_headers)
client = vision.ImageAnnotatorClient()
strm = request.files['fname'].stream
image = vision.Image(content=strm.read())
response = client.document_text_detection(image=image)
rslt = { "state": "OK" }
msg = []
for page in response.full_text_annotation.pages:
pg = []
for block in page.blocks:
pg_blk = []
for paragraph in block.paragraphs:
wrd = []
for word in paragraph.words:
word_text = ''.join([symbol.text for symbol in word.symbols])
wrd.append({ "Word": word_text, "confidence": word.confidence })
pg_blk.append({ "WordText": wrd })
pg.append({ "Paragraph": pg_blk })
msg.append({ "Page": pg })
rslt["message"] = msg
if response.error.message:
rslt = { "state": "NG", "message": response.error.message }
return (rslt, 200, res_headers)
return (rslt, 200, res_headers)
?♀️CROSヘッダーの設定
シレッとコードの先頭にある「Access-Control-Allow-Origin」のヘッダー設定
これの記述がないとブラウザ側でこんなエラーでた。
![]()
Access to XMLHttpRequest at '「Cloud FunctionsのURL」' from origin 'https://yizm.work' has been
blocked by CORS policy: No 'Access-Control-Allow-Origin' header is present on the requested resource.
この記事「CORS リクエストの処理」を参考に上記のコードを入れております。