CSVで取得したデータでWinActorの繰り返し処理したい。
特定の項目を使って別のCSVから項目に該当するコードを解決したい。
AccessやらExcelの機能使えって話もあるかもしれないけど、CSV同士を掛け合わせたいとか複雑な中間ファイル作りたくないって状況もあるかと思います。
はい、スクリプト実行ステージで作ってみました。
1.CSV同士を外部結合(LEFT JOINクエリ)
LEFT JOINとINNER JOINってどっちがどうだっけ?って話。
- LEFT JOIN ⇒ 左側の表は全レコード表示、右に特定項目がマッチした行だけくっつける
- INNER JOIN ⇒ 左右の表で特定項目がマッチした行だけ表示
今回、このスクリプトを作ったきっかけはOCRで読み取ったCSVレコードで項目紐づけだったので、「全角/半角」の区別でマッチしなかった場面があり、全部「半角化」してから比較しています。
項目名が空白の列は強制的に削除されます。
(WinActorが取り込む際、空白の項目名があると、それより右側の項目が読めなくなるので・・・)
スクリプト実行ステージのスクリプトタブに以下のコードを張り付ければ実装できます。
Dim AryVal()
Dim ApndVal()
Dim MrgCSV
Dim DicCSV
Dim DicCol
Set DicCSV = WScript.CreateObject("Scripting.Dictionary")
Set DicCol = WScript.CreateObject("Scripting.Dictionary")
MrgTxt = Read_TEXT(!元ファイル名!)
SrcTxt = Read_TEXT(!参照ファイル名!)
KeyCol = !キー項目!
OutPutFile = !出力ファイル名!
lnTXT = split(MrgTxt, vbCrLf)
RowBnd = UBound(lnTXT)
ReDim AryVal(RowBnd)
' 元CSVの辞書化
ColHeader = splitEx(lnTXT(0), NULL, NULL, NULL)
For i=0 To UBound(ColHeader)
ColName = ColHeader(i)
Erase AryVal
ReDim AryVal(RowBnd)
For j=1 To RowBnd
RowCols = splitEx(lnTXT(j), NULL, NULL, NULL)
If UBound(ColHeader) <= UBound(RowCols) Then
AryVal(j-1) = RowCols(i)
End If
Next
DicCSV.Add ColName, AryVal
Next
' 元ファイルCSVにそもそもキー項目がなかったらやめる
If Not DicCSV.Exists(KeyCol) Then
Err.Raise 404, "", "元ファイルCSVにキー項目名が見つかりませんでした。"
WScript.Quit
End If
' マージCSVの辞書化
lnTXT = split(SrcTxt, vbCrLf)
RowMrg = UBound(lnTXT)
' キー項目のカラムIndex番号を解決
ReDim ApndVal(RowMrg)
Erase AryVal
ReDim AryVal(RowBnd)
ColHeader = splitEx(lnTXT(0), NULL, NULL, NULL)
For i=0 To UBound(ColHeader)
ColName = ColHeader(i)
If Not DicCSV.Exists(ColName) Then DicCSV.Add ColName, AryVal
Next
For i=0 To UBound(ColHeader)
ColName = ColHeader(i)
Erase ApndVal
ReDim ApndVal(RowMrg)
For j=1 To RowMrg
RowCols = splitEx(lnTXT(j), NULL, NULL, NULL)
If UBound(ColHeader) <= UBound(RowCols) Then
ApndVal(j-1) = RowCols(i)
End If
Next
DicCol.Add ColName, ApndVal
Next
' 参照ファイルCSVにそもそもキー項目がなかったらやめる
If Not DicCol.Exists(KeyCol) Then
Err.Raise 404, "", "参照ファイルCSVにキー項目名が見つかりませんでした。"
WScript.Quit
End If
' 元ファイルのキー項目を使って該当するレコードの情報をマージする
Set objCWN = New CharWideNarrow
For i=0 To RowBnd
ArySrc = DicCSV(KeyCol)
If Len(ArySrc(i)) > 0 Then
For j=0 To RowMrg
AryMtch = DicCol(KeyCol)
If Len(AryMtch(j)) > 0 Then
Src = objCWN.ToNarrowAll(ArySrc(i))
Mtch = objCWN.ToNarrowAll(AryMtch(j))
If Src = Mtch Then
For Each k In DicCol.Keys()
If k <> KeyCol Then
AryTmp = DicCSV(k)
For l=0 To UBound(AryTmp)
AryVal(l) = AryTmp(l)
Next
AryVal(i) = DicCol(k)(j)
DicCSV(k) = AryVal
End If
Next
End If
End If
Next
End If
Next
If DicCSV.Exists("") Then DicCSV.Remove("")
' CSVに成形し直して出力
MrgCSV = ""
For Each k In DicCSV.Keys()
If Len(MrgCSV) > 0 Then MrgCSV = MrgCSV & ","
MrgCSV = MrgCSV & """" & k & """"
Next
For r=0 To RowBnd
lnVal = ""
For Each k In DicCSV.Keys()
If Len(lnVal) > 0 Then lnVal = lnVal & ","
lnVal = lnVal & """" & DicCSV(k)(r) & """"
Next
' 全項目が空白になってしまう行は捨てる。
If Len(Replace(Replace(lnVal, """", ""),",","")) > 0 Then
MrgCSV = MrgCSV & vbCrLf & lnVal
End If
Next
Write_TEXT MrgCSV, OutPutFile
Function Read_TEXT(FilePath)
Dim objFS, objTXT, Rslt
Set objFS = CreateObject("Scripting.FileSystemObject")
If objFS.FileExists(FilePath) Then
Set objTXT = objFS.OpenTextFile(FilePath, 1)
Rslt = objTXT.ReadAll()
objTXT.close
Set objTXT = Nothing
Else
Rslt = ""
End If
Set objFS = Nothing
Read_TEXT = Rslt
End Function
Function Write_TEXT(ContentStr, FilePath)
Dim objFS, objTXT
On Error Resume Next
Set objFS = CreateObject("Scripting.FileSystemObject")
Set objTXT = objFS.OpenTextFile(FilePath, 2, True)
objTXT.Write ContentStr
objTXT.close
Set objTXT = Nothing
Set objFS = Nothing
If Err.Number > 0 Then
Write_TEXT = False
Err.Clear
Else
Write_TEXT = True
End If
End Function
Class CharWideNarrow
Dim widedicASCII, widedicANK, narrowdicASCII, narrowdicANK
Dim x, i
Private Sub Class_Initialize()
'コンストラクタ
Set widedicASCII = CreateObject("Scripting.Dictionary")
Set widedicANK = CreateObject("Scripting.Dictionary")
Set narrowdicASCII = CreateObject("Scripting.Dictionary")
Set narrowdicANK = CreateObject("Scripting.Dictionary")
With narrowdicANK
'表の作成
.Add "゜", "゚"
.Add "゛", "゙"
.Add "ヴ", "ヴ"
.Add "ン", "ン"
.Add "ヲ", "ヲ"
.Add "ヱ", "ウェ"
.Add "ヰ", "ウィ"
.Add "ワ", "ワ"
.Add "ヮ", "ワ"
.Add "ロ", "ロ"
.Add "レ", "レ"
.Add "ル", "ル"
.Add "リ", "リ"
.Add "ラ", "ラ"
.Add "ヨ", "ヨ"
.Add "ョ", "ョ"
.Add "ユ", "ユ"
.Add "ュ", "ュ"
.Add "ヤ", "ヤ"
.Add "ャ", "ャ"
.Add "モ", "モ"
.Add "メ", "メ"
.Add "ム", "ム"
.Add "ミ", "ミ"
.Add "マ", "マ"
.Add "ポ", "ポ"
.Add "ボ", "ボ"
.Add "ホ", "ホ"
.Add "ペ", "ペ"
.Add "ベ", "ベ"
.Add "ヘ", "ヘ"
.Add "プ", "プ"
.Add "ブ", "ブ"
.Add "フ", "フ"
.Add "ピ", "ピ"
.Add "ビ", "ビ"
.Add "ヒ", "ヒ"
.Add "パ", "パ"
.Add "バ", "バ"
.Add "ハ", "ハ"
.Add "ノ", "ノ"
.Add "ネ", "ネ"
.Add "ヌ", "ヌ"
.Add "ニ", "ニ"
.Add "ナ", "ナ"
.Add "ド", "ド"
.Add "ト", "ト"
.Add "デ", "デ"
.Add "テ", "テ"
.Add "ヅ", "ヅ"
.Add "ツ", "ツ"
.Add "ッ", "ッ"
.Add "ヂ", "ヂ"
.Add "チ", "チ"
.Add "ダ", "ダ"
.Add "タ", "タ"
.Add "ゾ", "ゾ"
.Add "ソ", "ソ"
.Add "ゼ", "ゼ"
.Add "セ", "セ"
.Add "ズ", "ズ"
.Add "ス", "ス"
.Add "ジ", "ジ"
.Add "シ", "シ"
.Add "ザ", "ザ"
.Add "サ", "サ"
.Add "ゴ", "ゴ"
.Add "コ", "コ"
.Add "ゲ", "ゲ"
.Add "ケ", "ケ"
.Add "グ", "グ"
.Add "ク", "ク"
.Add "ギ", "ギ"
.Add "キ", "キ"
.Add "ガ", "ガ"
.Add "カ", "カ"
.Add "オ", "オ"
.Add "ォ", "ォ"
.Add "エ", "エ"
.Add "ェ", "ェ"
.Add "ウ", "ウ"
.Add "ゥ", "ゥ"
.Add "イ", "イ"
.Add "ィ", "ィ"
.Add "ア", "ア"
.Add "ァ", "ァ"
.Add "ー", "ー"
.Add "・", "・"
.Add "、", "、"
.Add "」", "」"
.Add "「", "「"
.Add "。", "。"
'逆引き表の作成
For Each x In .Keys
If widedicANK.Exists( .Item(x) ) = False Then
widedicANK.Add .Item(x), x
End If
Next
End With
With narrowdicASCII
'表の作成
.Add "~", "~"
.Add "}", "}"
.Add "|", "|"
.Add "{", "{"
.Add "z", "z"
.Add "y", "y"
.Add "x", "x"
.Add "w", "w"
.Add "v", "v"
.Add "u", "u"
.Add "t", "t"
.Add "s", "s"
.Add "r", "r"
.Add "q", "q"
.Add "p", "p"
.Add "o", "o"
.Add "n", "n"
.Add "m", "m"
.Add "l", "l"
.Add "k", "k"
.Add "j", "j"
.Add "i", "i"
.Add "h", "h"
.Add "g", "g"
.Add "f", "f"
.Add "e", "e"
.Add "d", "d"
.Add "c", "c"
.Add "b", "b"
.Add "a", "a"
.Add "‘", "`"
.Add "_", "_"
.Add "^", "^"
.Add "]", "]"
.Add "¥", "\"
.Add "[", "["
.Add "Z", "Z"
.Add "Y", "Y"
.Add "X", "X"
.Add "W", "W"
.Add "V", "V"
.Add "U", "U"
.Add "T", "T"
.Add "S", "S"
.Add "R", "R"
.Add "Q", "Q"
.Add "P", "P"
.Add "O", "O"
.Add "N", "N"
.Add "M", "M"
.Add "L", "L"
.Add "K", "K"
.Add "J", "J"
.Add "I", "I"
.Add "H", "H"
.Add "G", "G"
.Add "F", "F"
.Add "E", "E"
.Add "D", "D"
.Add "C", "C"
.Add "B", "B"
.Add "A", "A"
.Add "@", "@"
.Add "?", "?"
.Add ">", ">"
.Add "=", "="
.Add "<", "<"
.Add ";", ";"
.Add ":", ":"
.Add "9", "9"
.Add "8", "8"
.Add "7", "7"
.Add "6", "6"
.Add "5", "5"
.Add "4", "4"
.Add "3", "3"
.Add "2", "2"
.Add "1", "1"
.Add "0", "0"
.Add "/", "/"
.Add ".", "."
.Add "-", "-"
.Add ",", ","
.Add "+", "+"
.Add "*", "*"
.Add ")", ")"
.Add "(", "("
.Add "’", "'"
.Add "&", "&"
.Add "%", "%"
.Add "$", "$"
.Add "#", "#"
.Add "”", """"
.Add "!", "!"
.Add " ", " "
'逆引き表の作成
For Each x In .Keys
widedicASCII.Add .Item(x), x
Next
End With
End Sub
Private Sub Class_Terminated()
'デストラクタ
Set widedicASCII = Nothing
Set widedicANK = Nothing
Set narrowdicASCII = Nothing
Set narrowdicANK = Nothing
End Sub
Function ToNarrowAll( byref str )
Dim rtn, max_, char_, trns_
rtn = ""
max_ = len( str )
For i = 1 to max_
char_ = Mid( str,i,1 )
If narrowdicASCII.Exists( char_ ) Then
trns_ = narrowdicASCII.Item( char_ )
Else
If narrowdicANK.Exists( char_ ) Then
trns_ = narrowdicANK.Item( char_ )
Else
trns_ = char_
End If
End If
rtn = rtn & trns_
Next
ToNarrowAll = rtn
End Function
Function ToNarrowASCII( byref str )
Dim rtn, max_, char_, trns_
rtn = ""
max_ = len( str )
For i = 1 to max_
char_ = Mid( str,i,1 )
If narrowdicASCII.Exists( char_ ) Then
trns_ = narrowdicASCII.Item( char_ )
Else
trns_ = char_
End If
rtn = rtn & trns_
Next
ToNarrowASCII = rtn
End Function
Function ToNarrowKANA( byref str )
Dim rtn, max_, char_, trns_
rtn = ""
max_ = len( str )
For i = 1 to max_
char_ = Mid( str,i,1 )
If narrowdicANK.Exists( char_ ) Then
trns_ = narrowdicANK.Item( char_ )
Else
trns_ = char_
End If
rtn = rtn & trns_
Next
ToNarrowKANA = rtn
End Function
Function ToWideAll( byref str , byval option_ )
Dim rtn, max_, char_, trns_, next_c, flg_nextc_trns
rtn = ""
max_ = len( str ) - 1
flg_nextc_trns = False
For i = 1 to max_
If flg_nextc_trns = True Then
flg_nextc_trns = False
Else
char_ = Mid( str, i , 1 )
next_c = Mid( str, i+1 , 1 )
Select Case next_c
Case "゚" , "゙"
If widedicANK.Exists( char_ & next_c ) Then
char_ = char_ & next_c
flg_nextc_trns = True
End If
Case "ィ" , "ェ"
If Option_ Then
If widedicANK.Exists( char_ & next_c ) Then
char_ = char_ & next_c
flg_nextc_trns = True
End If
End If
Case Else
End Select
If widedicASCII.Exists( char_ ) Then
trns_ = widedicASCII.Item( char_ )
Else
If widedicANK.Exists( char_ ) Then
trns_ = widedicANK.Item( char_ )
Else
trns_ = char_
End If
End If
rtn = rtn & trns_
End If
Next
If flg_nextc_trns = False Then
char_ = Right( str, 1 )
If widedicASCII.Exists( char_ ) Then
trns_ = widedicASCII.Item( char_ )
Else
If widedicANK.Exists( char_ ) Then
trns_ = widedicANK.Item( char_ )
Else
trns_ = char_
End If
End If
rtn = rtn & trns_
End If
ToWideAll = rtn
End Function
Function ToWideASCII( byref str )
Dim rtn, max_, char_, trns_
rtn = ""
max_ = len( str )
For i = 1 to max_
char_ = Mid( str,i, 1 )
If widedicASCII.Exists( char_ ) Then
trns_ = widedicASCII.Item( char_ )
Else
trns_ = char_
End If
rtn = rtn & trns_
Next
ToWideASCII = rtn
End Function
Function ToWideKANA( byref str , byval option_ )
Dim rtn, max_, char_, trns_, next_c, flg_nextc_trns
rtn = ""
max_ = len( str ) - 1
flg_nextc_trns = False
For i = 1 to max_
If flg_nextc_trns = True Then
flg_nextc_trns = False
Else
char_ = Mid( str, i , 1 )
next_c = Mid( str, i+1 , 1 )
Select Case next_c
Case "゚" , "゙"
If widedicANK.Exists( char_ & next_c ) Then
char_ = char_ & next_c
flg_nextc_trns = True
End If
Case "ィ" , "ェ"
If option_ Then
If widedicANK.Exists( char_ & next_c ) Then
char_ = char_ & next_c
flg_nextc_trns = True
End If
End If
Case Else
End Select
If widedicANK.Exists( char_ ) Then
trns_ = widedicANK.Item( char_ )
Else
trns_ = char_
End If
rtn = rtn & trns_
End If
Next
If flg_nextc_trns = False Then
char_ = Right( str, 1 )
If widedicANK.Exists( char_ ) Then
trns_ = widedicANK.Item( char_ )
Else
trns_ = char_
End If
rtn = rtn & trns_
End If
ToWideKANA = rtn
End Function
End Class
' 引用: http://blog.livedoor.jp/tea_cocoa_cake/archives/5356742.html
'! Split()のテキスト区切り対応版
'! テキスト区切り文字(例CSVの")に対応した区切りを行う
'! @param source 元文字列
'! @param colDelim 列区切り文字(NULL可、NULLの場合「,」使用)
'! @param lineDelim 行区切り文字(NULL可、NULLの場合vbCrLfを使用)
'! @param textDelim テキスト区切り文字(NULL可、NULLの場合「"」を使用) (textDelim2つでテキスト区切り文字エスケープ)
'! @return 1次元配列 (改行がある場合は配列要素としてvbNullChar単体が格納される
public function splitEx(source, colDelim, lineDelim, textDelim)
splitEx = NULL
dim textMode: textMode = False
if (isNull(colDelim) ) Then
colDelim = ","
end if
if (isNull(lineDelim) ) Then
lineDelim = vbCrLf
end if
if (isNull(textDelim) ) Then
textDelim = """"
end if
dim ab : set ab = New ArrayBuilder
dim textBuf : textBuf = "" ' テキストバッファ
dim char_i : char_i = 1 ' 文字列のインデックス
Do while (char_i <= len(source))
dim curChar : curChar = getChar(source, char_i)
if(textMode = True) Then
select case curChar
case textDelim
'! 1文字先読み And エスケープ判定
if ( getChar(source, char_i + 1) = textDelim ) Then
' エスケープ
textBuf = textBuf & getChar(source, char_i + 1)
char_i = char_i + 1 ' 先読み分カウンタを加算
else
' テキストモードOFF
textMode = False
end if
case Else
textBuf = textBuf & curChar
end select
else
select case curChar
case colDelim
ab.add textBuf
textBuf = ""
case lineDelim
ab.add textBuf
ab.add vbNullChar ' 改行を示す
textBuf = ""
case vbCr
'! 1文字先読み And lineDelim=vbCrLf(※2文字)の場合の特殊な判定
if ( getChar(source, char_i + 1) = vbLf And lineDelim = vbCrLf ) Then
ab.add textBuf
ab.add vbNullChar ' 改行を示す
textBuf = ""
char_i = char_i + 1 ' 先読み分カウンタを加算
else
textBuf = textBuf & curChar
end if
case textDelim
' テキストモードON
textMode = True
case Else
textBuf = textBuf & curChar
end select
end if
char_i = char_i + 1
loop
' 最後にテキストバッファの残りを処理
ab.add textBuf
splitEx = ab.toArray()
end function
'! 文字列から1文字取得。文字列終端(VBScripでは通常参照しない)の場合ではvbNullChar(00)を返す
'! @param source 元文字列
'! @param index 文字列のインデックス
'! @return 文字
private function getChar(source, index)
getChar = ""
if (index <= 0 Or index > (len(source) + 1) ) Then
err.raise 1025,,"範囲外の参照"
exit function
end if
' 文字列終端の場合
if (index = (len(source) + 1) ) Then
getChar = vbNullChar
end if
getChar = mid(source, index, 1)
end function
'! 配列生成
class ArrayBuilder
private my_lastIndex
private my_array()
Public Sub Class_Initialize
dim INITIAL_SIZE : INITIAL_SIZE = 8
my_lastIndex = -1
redim Preserve my_array(INITIAL_SIZE - 1) ' 注意...配列は(指定サイズ + 1)のサイズで領域が確保される
End Sub
Public Sub Class_Terminate
End Sub
'! 値の参照
'! @param index 配列インデックス
'! @return 値
public property get item(index)
if (index < 0 Or index > my_lastIndex) Then
err.raise 1025,,"範囲外の参照"
exit property
end if
item = my_array(index)
end property
'! 値のセット
'! @param index 配列インデックス
'! @param value 値
public property let item(index, value)
if (index < 0) Then
err.raise 1025,,"範囲外の参照"
exit property
end if
' Expand
Do While (index >= getSize() )
call expand()
Loop
if (index > my_lastIndex) Then
my_lastIndex = index
end if
my_array(index) = value
end property
'! 最後尾に値の追加
'! @param value 値
public sub add(value)
me.item(my_lastIndex + 1) = value
end sub
'! 配列拡張
private sub expand()
'+ wscript.echo "#Expanded!"
' 再確保のオーバヘッド軽減のため大きめにサイズを拡張
redim Preserve my_array(getSize() * 2 - 1)
end sub
'! 配列サイズ取得
'! @return 現在の配列サイズ
private function getSize()
'+ wscript.echo "#size:" & UBound(my_array) - LBound(my_array) + 1
getSize = UBound(my_array) - LBound(my_array) + 1
end function
'! 要素に合わせて配列サイズを縮小
'! @param arr 配列
'! @return 縮小後の配列
private function fit(ByRef arr)
redim Preserve arr(my_lastIndex)
fit = arr
end function
'! 配列を返す
'! @return 配列
public function toArray()
dim tmpArray : tmpArray = my_array
tmpArray = fit(tmpArray)
toArray = tmpArray
end function
end class
2.設定タブはこんな感じ。
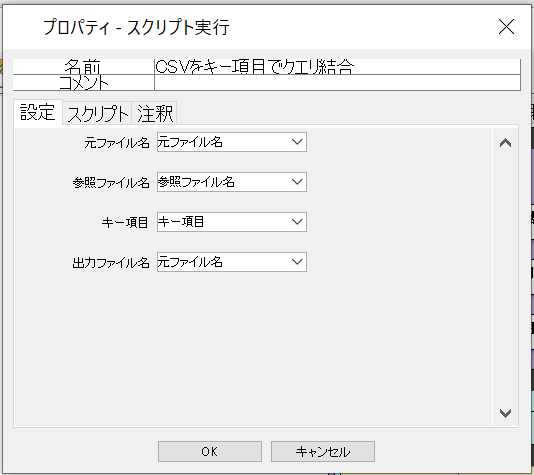
- 元ファイル名 : 結合時に左側になるCSVファイルを指定
- 参照ファイル名: 結合時に右側になるCSVファイルを指定
- キー項目 :左右のCSVを関連付けする主キーの項目名を指定
- 出力ファイル名: 結合後のCSVを出力するファイル名を指定
3.適用イメージはこんな感じ。
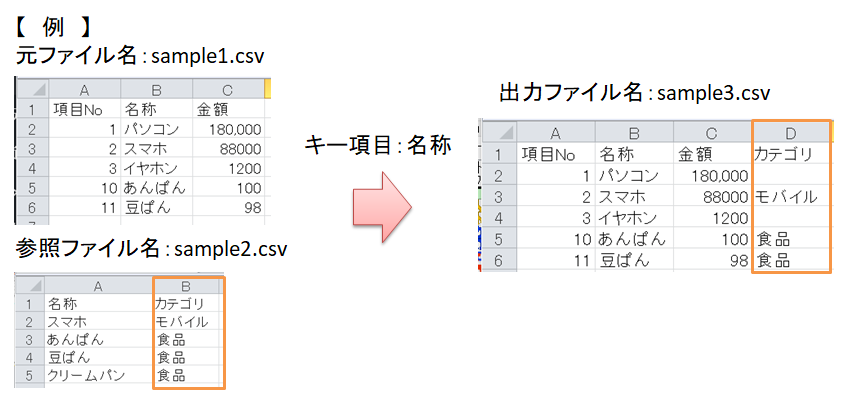
参照ファイルの方は右に項目がたくさんあっても全部追加されます。
途中でリスト削っちゃったら未処理の結果リスト残せないので、突合できない項目は空白にしてレコードは残します。