CSVで取得したデータでWinActorの繰り返し処理したい。
CSVは所定のフォルダに各担当がポンポンいれて、順番に処理したい。
とりあえず、CSVをマージして1つのファイルにまとめてから繰り返し処理で使いたいなーって思いますよね。
はい、スクリプト実行ステージで作ってみました。
1.CSVファイルをひとつにまとめる(UNIONクエリ的な?)
ここが可愛いポイント♪
- ちゃんと、CSVの項目名を見て列の順番が違くても同じ項目の列にデータを追加して行追加してくれます。
- 元ファイルにない項目名が追加CSVに含まれていても、元ファイル側に項目を追加して行追加してくれます。
- 全項目が、ダブルクオーテーションありの区切りリストに変換されます。
項目名が空白の列は強制的に削除されます。
(WinActorが取り込む際、空白の項目名があると、それより右側の項目が読めなくなるので・・・)
項目の順番を気にしなくて良いっていうのは、OCRと組み合わせて使う際に強力な効果を生み出しますね。
スクリプト実行ステージのスクリプトタブに以下のコードを張り付ければ実装できます。
Dim AryVal()
Dim MstrCSV
Dim ApndCSV
Set MstrCSV = WScript.CreateObject("Scripting.Dictionary")
MasterFile = !マスター出力ファイル!
ImportFile = !取り込みファイル名!
' マスターCSVの辞書化
txtVal = Read_TEXT(MasterFile)
lnTXT = split(txtVal, vbCrLf)
RowBnd = UBound(lnTXT)
If Len(txtVal) > 0 Then
ColHeader = splitEx(lnTXT(0), NULL, NULL, NULL)
For i=0 To UBound(ColHeader)
ColName = ColHeader(i)
Erase AryVal
ReDim AryVal(RowBnd)
For j=1 To RowBnd
RowCols = splitEx(lnTXT(j), NULL, NULL, NULL)
If UBound(ColHeader) <= UBound(RowCols) Then
AryVal(j-1) = RowCols(i)
End If
Next
MstrCSV.Add ColName, AryVal
Next
End If
' 取り込みCSVの追加
txtVal = Read_TEXT(ImportFile)
lnTXT = split(txtVal, vbCrLf)
RowMrg = UBound(lnTXT)
TotalBnd = RowBnd + RowMrg
ColHeader = splitEx(lnTXT(0), NULL, NULL, NULL)
' 辞書の拡張
Dim tmpAry
' 既存カラムの行を拡張
Erase AryVal
ReDim AryVal(TotalBnd)
For Each k In MstrCSV.Keys()
tmpAry = MstrCSV(k)
For i=0 To UBound(tmpAry)
AryVal(i) = tmpAry(i)
Next
MstrCSV(k) = AryVal
Next
' 未知カラムの定義拡張
Erase AryVal
ReDim AryVal(TotalBnd)
For i=0 To UBound(ColHeader)
ColName = ColHeader(i)
If Not MstrCSV.Exists(ColName) Then
MstrCSV.Add ColName, AryVal
End If
Next
For i=0 To UBound(ColHeader)
ColName = ColHeader(i)
Erase AryVal
ReDim AryVal(TotalBnd)
tmpAry = MstrCSV(ColName)
For j=0 To UBound(tmpAry)
AryVal(j) = tmpAry(j)
Next
For j=1 To RowMrg
RowCols = splitEx(lnTXT(j), NULL, NULL, NULL)
If UBound(ColHeader) <= UBound(RowCols) Then
AryVal(j + RowBnd) = RowCols(i)
End If
Next
MstrCSV(ColName) = AryVal
Next
If MstrCSV.Exists("") Then MstrCSV.Remove("")
' CSVに成形し直して出力
MrgCSV = ""
For Each k In MstrCSV.Keys()
If Len(MrgCSV) > 0 Then MrgCSV = MrgCSV & ","
MrgCSV = MrgCSV & """" & k & """"
Next
For r=0 To TotalBnd
lnVal = ""
For Each k In MstrCSV.Keys()
If Len(lnVal) > 0 Then lnVal = lnVal & ","
lnVal = lnVal & """" & MstrCSV(k)(r) & """"
Next
' 全項目が空白になってしまう行は捨てる。
If Len(Replace(Replace(lnVal, """", ""),",","")) > 0 Then
MrgCSV = MrgCSV & vbCrLf & lnVal
End If
Next
Write_TEXT MrgCSV, MasterFile
Function Read_TEXT(FilePath)
Dim objFS, objTXT, Rslt
Set objFS = CreateObject("Scripting.FileSystemObject")
If objFS.FileExists(FilePath) Then
Set objTXT = objFS.OpenTextFile(FilePath, 1)
Rslt = objTXT.ReadAll()
objTXT.close
Set objTXT = Nothing
Else
Rslt = ""
End If
Set objFS = Nothing
Read_TEXT = Rslt
End Function
Function Write_TEXT(ContentStr, FilePath)
Dim objFS, objTXT
On Error Resume Next
Set objFS = CreateObject("Scripting.FileSystemObject")
Set objTXT = objFS.OpenTextFile(FilePath, 2, True)
objTXT.Write ContentStr
objTXT.close
Set objTXT = Nothing
Set objFS = Nothing
If Err.Number > 0 Then
Write_TEXT = False
Err.Clear
Else
Write_TEXT = True
End If
End Function
' 引用: http://blog.livedoor.jp/tea_cocoa_cake/archives/5356742.html
'! Split()のテキスト区切り対応版
'! テキスト区切り文字(例CSVの")に対応した区切りを行う
'! @param source 元文字列
'! @param colDelim 列区切り文字(NULL可、NULLの場合「,」使用)
'! @param lineDelim 行区切り文字(NULL可、NULLの場合vbCrLfを使用)
'! @param textDelim テキスト区切り文字(NULL可、NULLの場合「"」を使用) (textDelim2つでテキスト区切り文字エスケープ)
'! @return 1次元配列 (改行がある場合は配列要素としてvbNullChar単体が格納される
public function splitEx(source, colDelim, lineDelim, textDelim)
splitEx = NULL
dim textMode: textMode = False
if (isNull(colDelim) ) Then
colDelim = ","
end if
if (isNull(lineDelim) ) Then
lineDelim = vbCrLf
end if
if (isNull(textDelim) ) Then
textDelim = """"
end if
dim ab : set ab = New ArrayBuilder
dim textBuf : textBuf = "" ' テキストバッファ
dim char_i : char_i = 1 ' 文字列のインデックス
Do while (char_i <= len(source))
dim curChar : curChar = getChar(source, char_i)
if(textMode = True) Then
select case curChar
case textDelim
'! 1文字先読み And エスケープ判定
if ( getChar(source, char_i + 1) = textDelim ) Then
' エスケープ
textBuf = textBuf & getChar(source, char_i + 1)
char_i = char_i + 1 ' 先読み分カウンタを加算
else
' テキストモードOFF
textMode = False
end if
case Else
textBuf = textBuf & curChar
end select
else
select case curChar
case colDelim
ab.add textBuf
textBuf = ""
case lineDelim
ab.add textBuf
ab.add vbNullChar ' 改行を示す
textBuf = ""
case vbCr
'! 1文字先読み And lineDelim=vbCrLf(※2文字)の場合の特殊な判定
if ( getChar(source, char_i + 1) = vbLf And lineDelim = vbCrLf ) Then
ab.add textBuf
ab.add vbNullChar ' 改行を示す
textBuf = ""
char_i = char_i + 1 ' 先読み分カウンタを加算
else
textBuf = textBuf & curChar
end if
case textDelim
' テキストモードON
textMode = True
case Else
textBuf = textBuf & curChar
end select
end if
char_i = char_i + 1
loop
' 最後にテキストバッファの残りを処理
ab.add textBuf
splitEx = ab.toArray()
end function
'! 文字列から1文字取得。文字列終端(VBScripでは通常参照しない)の場合ではvbNullChar(00)を返す
'! @param source 元文字列
'! @param index 文字列のインデックス
'! @return 文字
private function getChar(source, index)
getChar = ""
if (index <= 0 Or index > (len(source) + 1) ) Then
err.raise 1025,,"範囲外の参照"
exit function
end if
' 文字列終端の場合
if (index = (len(source) + 1) ) Then
getChar = vbNullChar
end if
getChar = mid(source, index, 1)
end function
'! 配列生成
class ArrayBuilder
private my_lastIndex
private my_array()
Public Sub Class_Initialize
dim INITIAL_SIZE : INITIAL_SIZE = 8
my_lastIndex = -1
redim Preserve my_array(INITIAL_SIZE - 1) ' 注意...配列は(指定サイズ + 1)のサイズで領域が確保される
End Sub
Public Sub Class_Terminate
End Sub
'! 値の参照
'! @param index 配列インデックス
'! @return 値
public property get item(index)
if (index < 0 Or index > my_lastIndex) Then
err.raise 1025,,"範囲外の参照"
exit property
end if
item = my_array(index)
end property
'! 値のセット
'! @param index 配列インデックス
'! @param value 値
public property let item(index, value)
if (index < 0) Then
err.raise 1025,,"範囲外の参照"
exit property
end if
' Expand
Do While (index >= getSize() )
call expand()
Loop
if (index > my_lastIndex) Then
my_lastIndex = index
end if
my_array(index) = value
end property
'! 最後尾に値の追加
'! @param value 値
public sub add(value)
me.item(my_lastIndex + 1) = value
end sub
'! 配列拡張
private sub expand()
'+ wscript.echo "#Expanded!"
' 再確保のオーバヘッド軽減のため大きめにサイズを拡張
redim Preserve my_array(getSize() * 2 - 1)
end sub
'! 配列サイズ取得
'! @return 現在の配列サイズ
private function getSize()
'+ wscript.echo "#size:" & UBound(my_array) - LBound(my_array) + 1
getSize = UBound(my_array) - LBound(my_array) + 1
end function
'! 要素に合わせて配列サイズを縮小
'! @param arr 配列
'! @return 縮小後の配列
private function fit(ByRef arr)
redim Preserve arr(my_lastIndex)
fit = arr
end function
'! 配列を返す
'! @return 配列
public function toArray()
dim tmpArray : tmpArray = my_array
tmpArray = fit(tmpArray)
toArray = tmpArray
end function
end class
2.設定タブはこんな感じ。
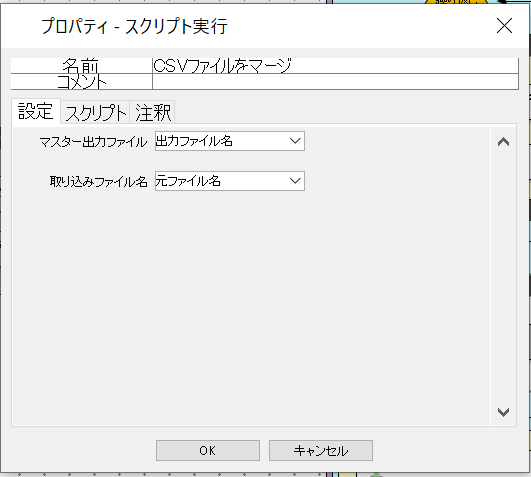
- マスター出力ファイル : データ吸収する方のCSVファイルをフルパス指定(上書きされます)
- 取り込みファイル名 : 取り込みされる方のCSVファイルをフルパス指定
マスター出力ファイルは、ファイルの無いパスを指定しても取り込みファイルだけのデータでそこにファイルを生成してくれます。
[WinActor]フォルダ内のファイルを順に処理するシナリオ
↑この記事で紹介したフォルダ内のファイルを順次処理する「何かの処理」のところに配置して使えば、所定のフォルダ内のCSVファイルをすべて1つのCSVファイルにマージすることができる訳ですねぃ。
それから「繰り返し」ノードの「データ数」オプションでデータファイルにCSVを指定すれば、全レコードの処理ができちゃう訳ですねぃ。
3.適用イメージはこんな感じ。

マスターファイルは上書きなので注意してねー。
イメージの例では、「個数」っていう新しい列があったら追加されるって表現してます。
ちゃんと同じ項目だったら何も項目増えないし、項目の並び順が違くても大丈夫ですよん。